머신러닝 목차 : https://wondangcom.tistory.com/2769
머신러닝 목차
머신러닝 1. 머신러닝 소개 1.1 인공지능이란 (혼공머신) - 4차산업 혁명 시대에 꼭 필요한 인공지능에 대해 알아 보자. 링크 : https://wondangcom.tistory.com/2771(2024.3.7) 1.2 머신러닝을 사용하는 이유 (핸
wondangcom.tistory.com
목표
- 예측 후 산점도를 그려 보고 해당 위치에 예측 결과가 맞는지 살펴 보자.
데이터셋 출처
Male Female determination-KNN, logistic regression
Explore and run machine learning code with Kaggle Notebooks | Using data from Male & Female height and weight
www.kaggle.com
1. 데이터셋 분석
- Height : 키(cm)
- Weight : 몸무게(kg)
- Sex : 성별(Female/Male)
2. 데이터셋 로딩
1. 데이터를 다루기 위한 라이브러리 임포트
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. 훈련데이터셋 로딩
df= pd.read_csv("/content/drive/MyDrive/dataset/MaleFemaleDataset/Training set.csv")
df.head()
여기서 데이터셋은 구글 드라이브에 업로드 해 둔 상태이다.
3. 데이터셋의 자료형과 Null 값이 있는지 확인
- 자료형 확인
df.info()
Heigth,Weight는 숫자형 Sex 는 문자형이다.
- Null 값 체크
df.isnull().sum()
3000개의 데이터 중에 Null 값은 없기 때문에 특별한 작업 없이 모델을 훈련하면 될 것 같다.
3. 테스트셋과 훈련셋 분할
1. 데이터 분리하여 모양 출력
X=df[['Height','Weight']]
y=df['Sex']
#훈련 데이터와 테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=42)
#데이터 모양을 출력해 보자.
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
3000개의 데이터셋트가 2250개의 훈련데이터와 750개의 테스트 세트로 분할 된 것을 확인 할 수 있다.
4. 학습
- 최근접 이웃 모델을 이용하여 학습해 본다.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)- 훈련데이터셋의 점수 확인
model.score(X_train, y_train)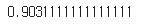
- 테스트 셋의 점수 확인
model.score(X_test, y_test)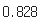
5. 예측
그렇다면 146.32cm 의 키에 59.8kg인 몸무게를 가진 사람은 남자일까 여자일까 이 모델을 이용해서 예측을 해 보자.
model.predict([[146.32, 59.8]])
예측을 하는 것은 predict 이다. predict 에 훈련 데이터셋과 동일한 모양의 키,몸무게 데이터를 리스트 형태로 넣어 주면 해당 데이터셋의 결과를 돌려 준다.
이 모델에서는 Female로 예측을 했다.
그렇다면 이 데이터가 맞는지 산점도를 그려서 확인을 해 보도록 한다.
6. 산점도 그리기
1. 여자 데이터와 남자 데이터 분리하기
import matplotlib.pyplot as plt
#여자 데이터 생성
female = df[df['Sex'] == 'Female']
female.head()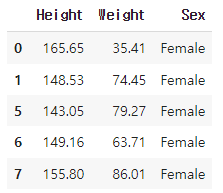
여성 데이터만 추출하여 female 에 담는다.
df['sex']=='Female' 는 sex 가 Female 인 경우에만 참, 아니면 거짓이 나오므로 전체데이터(df) 에서 참인 데이터만 추출 하므로 여성 데이터만 추출이 된다.
#남자 데이터 생성
male = df[df['Sex'] == 'Male']
male.head()
2. 산점도 그려 보기
plt.scatter(female['Height'],female['Weight'],label='female')
plt.scatter(male['Height'],male['Weight'],label='male')
plt.scatter(146.32, 59.8,marker='^')
plt.xlabel('Height')
plt.ylabel('Weight')
plt.legend()
plt.show()
산점도는 matplotlib 의 scatter 을 사용하여 출력한다.
scatter를 차례 차례 쌓으면 해당 값에 색상이 서로 다른 색상으로 표시된다.
legend 는 범례를 표시하겠다는 메서드로 scatter에 있는 label 값을 기준으로 범례를 생성한다.
너무 멀리 떨어져 있는 수가 두개가 있다. 키가 200이 넘어가는 것이나 몸무게가 200을 넘어 가는 것은 문제가 있어 보인다. 이 데이터를 삭제하고 다시 그려 보자.
또한 현재 male 값 위치에 예측 데이터가 있는 것으로 보인다. 이것은 female를 먼저 출력하고 그 다음 male 를 출력하여 덮어 쓴 형태이다. 이것을 투명도를 0.1로 하여 출력해 본다
#여자 데이터 생성
female = df[ (df['Sex'] == 'Female') & (df['Height'] < 200) & (df['Weight'] < 200)]
#남자 데이터 생성
male = df[(df['Sex'] == 'Male')& (df['Height'] < 200) & (df['Weight'] < 200)]
plt.scatter(female['Height'],female['Weight'],label='female',alpha=0.1)
plt.scatter(male['Height'],male['Weight'],label='male',alpha=0.1)
plt.scatter(146.32, 59.8,marker='^')
plt.xlabel('Height')
plt.ylabel('Weight')
plt.legend()
plt.show()
이렇게 확대해서 보니 파랑색이 female 이고 투명도를 0.1로 만들어서 확인하니 해당 지점이 파랑색이 많다는 것은 female 이 많다는 것이므로 정확히 예측했다고 볼 수 있다.
참고) https://www.kaggle.com/code/yungbyun/female-male-classification-with-functions
Female/Male Classification with functions
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
Male Female determination-KNN, logistic regression
Explore and run machine learning code with Kaggle Notebooks | Using data from Male & Female height and weight
www.kaggle.com
'강의자료 > 머신러닝' 카테고리의 다른 글
| 3.1 선형 회귀 (7) | 2024.05.09 |
|---|---|
| 2.1 데이터 다루기 - 데이터 전처리 필요성 (9) | 2024.05.02 |
| 2.1 데이터다루기 - 최근접 이웃 분류 (10) | 2024.04.19 |
| 1.6 머신러닝 과정 (0) | 2024.04.11 |
| 1.5 머신러닝의 모델 구분 (0) | 2024.04.04 |