| 학습목표 |
타이타닉호의 침몰은 역사상 가장 악명 높은 난파선 중 하나입니다.
이 챌린지에서는 어떤 종류의 사람들이 생존할 가능성이 더 높았습니까? 라는 질문에 답하는 예측 모델을 구축하도록 요청합니다.
캐글에서 타이타닉 문제를 해결해 봅니다.
| 경진대회 참여 |
1. https://www.kaggle.com/c/titanic 에 접속합니다.
2. Data 카테고리를 클릭하면 다음과 같이 훈련세트와 테스트 세트가 존재합니다.

훈련세트의 필드명의 조건을 확인 합니다.
3. code 를 클릭하여 새로운 노트를 만듭니다.
Data 클릭하여 다음과 같이 3개의 파일을 확인 합니다.
4. 데이터 살펴 보기
import pandas as pd
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
submission = pd.read_csv('/kaggle/input/titanic/gender_submission.csv')
print(train.head())
print(test.head())
print(submission.head())train 데이터에는 Survived 가 포함되어 있고 test 데이터에는 없습니다. test 파일을 예측하여 각 PassengerID의 Survived 를 예측하여 제출하는 문제인 것을 알 수 있습니다.
- train 정보 살펴 보기
train.info()총 891건 중 Age,Cabin,Embarked 특성이 정확한 정보가 들어가 있지 않은 것을 알 수 있습니다.
- 데이터 시각화 하여 특징 살펴 보기
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
def bar_chart(feature):
survived = train.loc[train["Survived"]==1,feature].value_counts() #해당 특징의 Survived 가 1인 갯수를 세어준다.
dead = train.loc[train["Survived"]==0,feature].value_counts()
data = pd.DataFrame([survived,dead],index = ["Survived","Dead"])
data.plot(kind="bar",figsize=(15,10))
plt.show()
#pclass에 따른 생존/사망자 확인
bar_chart("Pclass")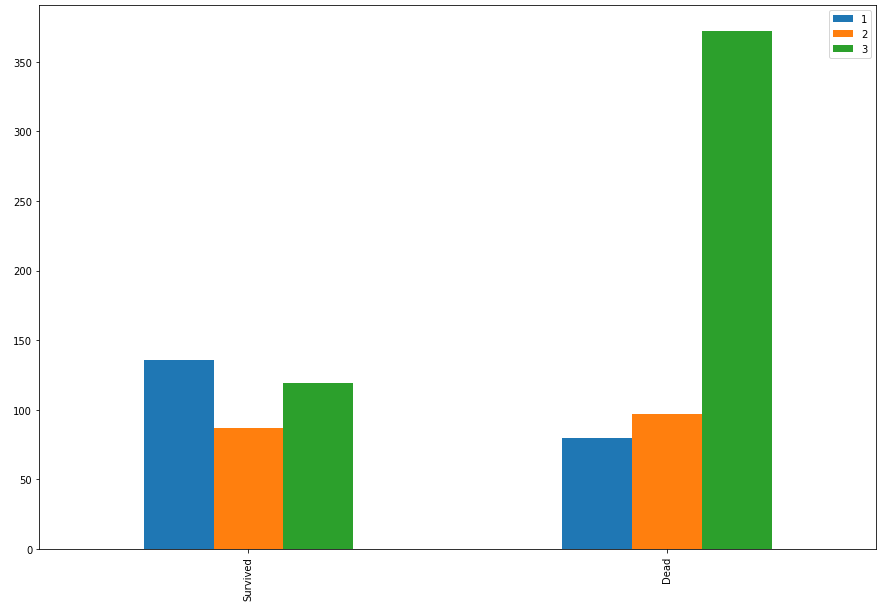
1등석은 생존자가 더 많고 3등석은 사망자가 더 많은 것을 확인 할 수 있습니다.
따라서 pclass 특징은 지도 학습에 가져 가는 것이 좋다는 것을 판단 할 수 있습니다.
#fare 에 따른 생존/사망자 확인
facet = sns.FacetGrid(train,hue='Survived',aspect=4)
facet.map(sns.kdeplot,'Fare',shade=True)
facet.set(xlim=(0,train['Fare'].max()))
facet.add_legend()
plt.xlim(0,180)
plt.show()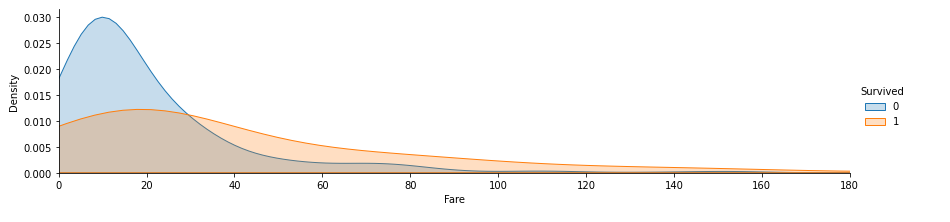
Fare(요금)가 낮을 수록 사망자가 높은것을 알 수 있습니다. 따라서 Fare 도 지도학습에 가져 가는 것이 좋을것 같습니다.
#sex 에 따른 생존/사망자 확인
bar_chart('Sex')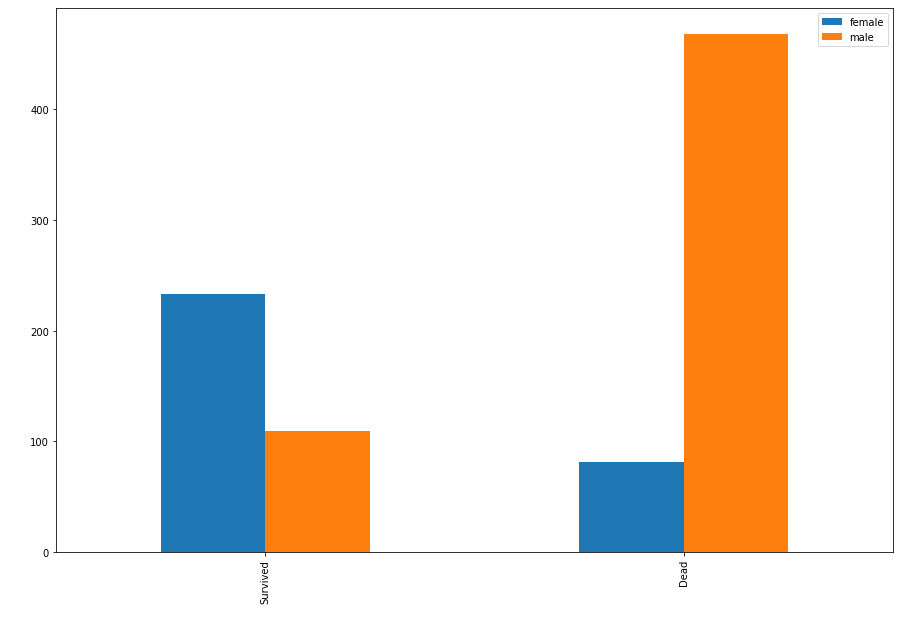
남자보다 여자가 생존자가 더 많은 것을 알 수 있네요. 역시 지도학습의 특징으로 사용하면 좋을 것 같습니다.
#age 에 따른 생존/사망자 확인
facet = sns.FacetGrid(train,hue='Survived',aspect=4)
facet.map(sns.kdeplot,'Age',shade=True)
facet.set(xlim=(0,train['Age'].max()))
facet.add_legend()
plt.xlim(0,180)
plt.show()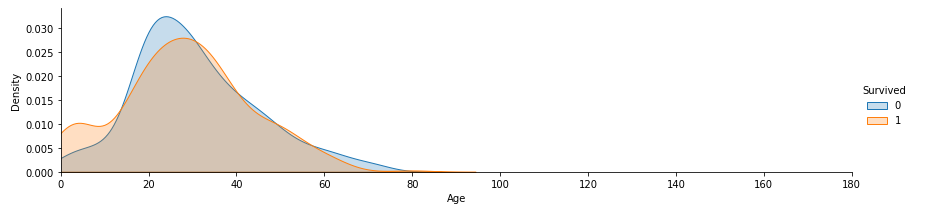
나이가 어릴 수록 생존율이 높네요.
sibsp(혼자 탔는지 0, n명의 친인척과 같이 탔는지) + parch(혼자 탔는지 0,n명의 부모 자식과 같이 탔는지) 를 합해서 가족이 같이 탄 경우의 특징을 만들어서 가족과 같이 탔을때는 어떤지 살펴 봅니다.
train['Familysize']=train['SibSp'] + train['Parch']
#train.drop('SibSp',axis=1,inplace=True)
#train.drop('Parch',axis=1,inplace=True)
bar_chart('Familysize')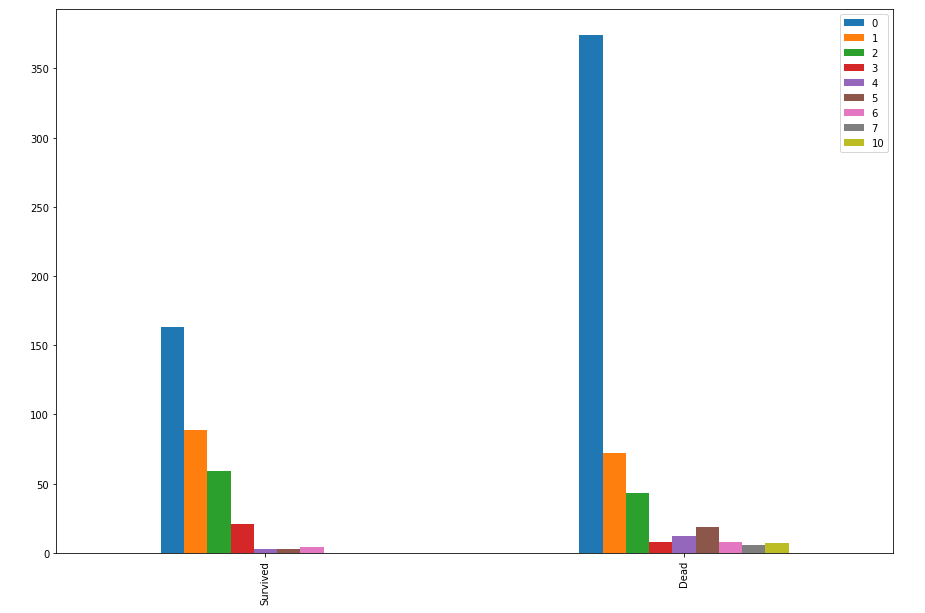
혼자 탄 경우가 사망율이 월등히 많은 것을 알 수 있습니다. 아마도 물에 빠졌을때 가족끼로 서로 껴안고 몸을 녹여서 살 확률이 높았을 수 도 있을것 같네요. 이 특징도 지도학습에서 사용하면 유용할 것 같습니다.
어느 선착장에서 탔는지도 살펴 봅시다.
#embarked 에 따른 생존/사망자
bar_chart('Embarked')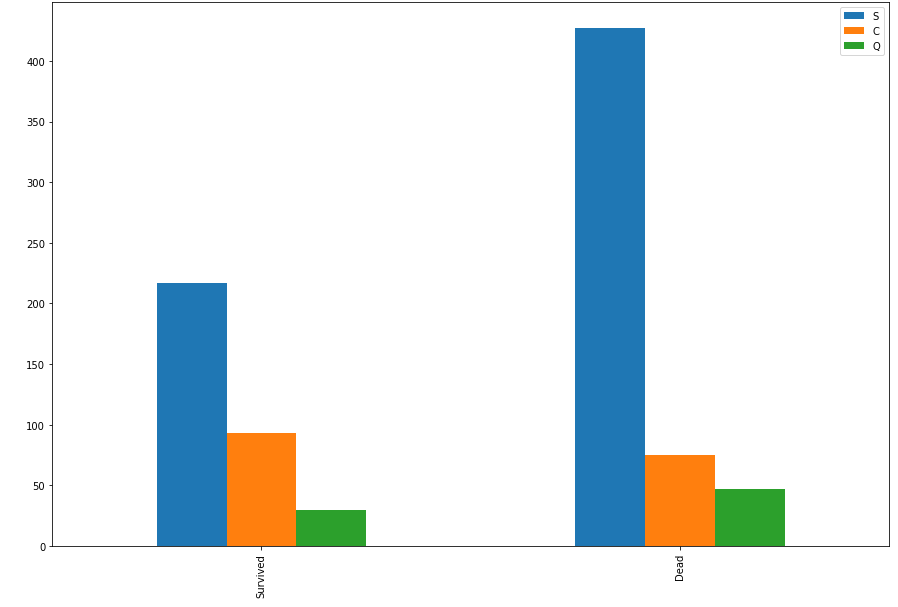
C 선착장에서 탄 고객이 살 확률이 높네요~
Cabin 은 결측치 값이 많아서 유용하게 사용할 수가 없네요.
Name과 생존 확률은 의미가 없을 것입니다. 꼭 사용해야 한다면 아마도 Name에서 Mr,Miss 등을 찾아서 성별을 구별하는 정도 일것 같은데 여기서는 Sex 특징이 있으므로 사용할 필요가 없어 보입니다.
Ticket 번호 역시 무의미한 데이터 입니다.
그렇다면 여기서 가져가야 하는 특징을 Pclass,Sex,Age,SibSp,Parch,Fare,Embarked 로 찾을 수 있습니다.
5. 데이터 가공
여기서 Age 데이터에 결측치가 발생했으므로 이 특성의 값을 다음과 같이 평균으로 결측치를 채웁니다.
#age 결측치 처리
#평균으로 결측치 채우기
train['Age'].fillna(train['Age'].mean(axis=0),inplace=True)다음으로 나이별 구간화를 진행하겠습니다. 데이터가 많으면 학습에 영향을 미치기 때문에 다음과 같이 청소년,청년,장년,중년,노년의 구간화를 진행합니다.
# age 구간화
# 청소년 : 0
# 청년 : 1
# 장년 : 2
# 중년 : 3
# 노년 : 4
ranges=[0,16,26,36,62,100]
labels=[0,1,2,3,4]
train["AgeGroup"]=pd.cut(train['Age'],ranges,right=False,labels=labels)
train.head()
요금도 구간화를 진행하겠습니다.
# fare 구간화
ranges=[0,17,30,100,1000]
labels=[0,1,2,3]
train["FareGroup"]=pd.cut(train['Fare'],ranges,right=False,labels=labels)
train.head()
성별을 문자에서 숫자로 변경을 합니다.
#성별을 숫자로 매핑
train['SexNum']=train['Sex'].apply(lambda x:1 if (x=='female') else 0)
train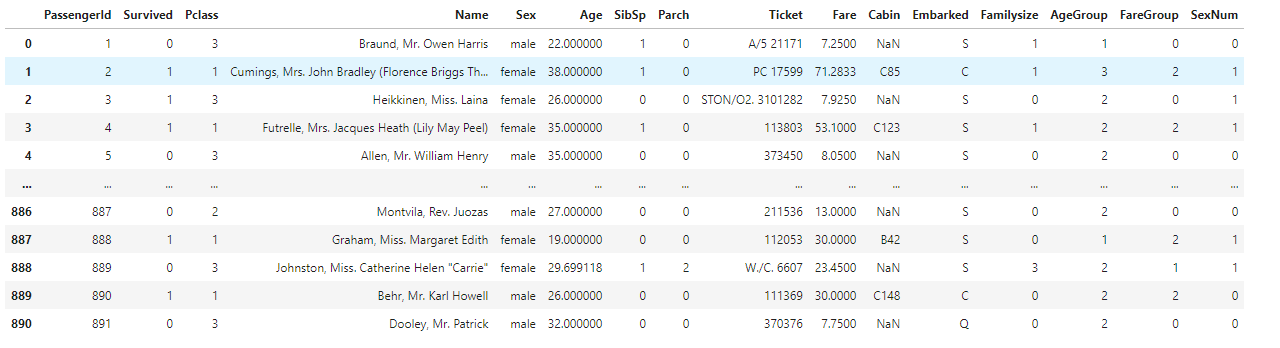
선착장 코드를 문자에서 숫자로 변경합니다.
#embarked을 숫자로 매핑
train['EmbarkedNum']=train['Embarked'].apply(lambda x:0 if (x=='S') else (1 if(x=='C') else 2))
train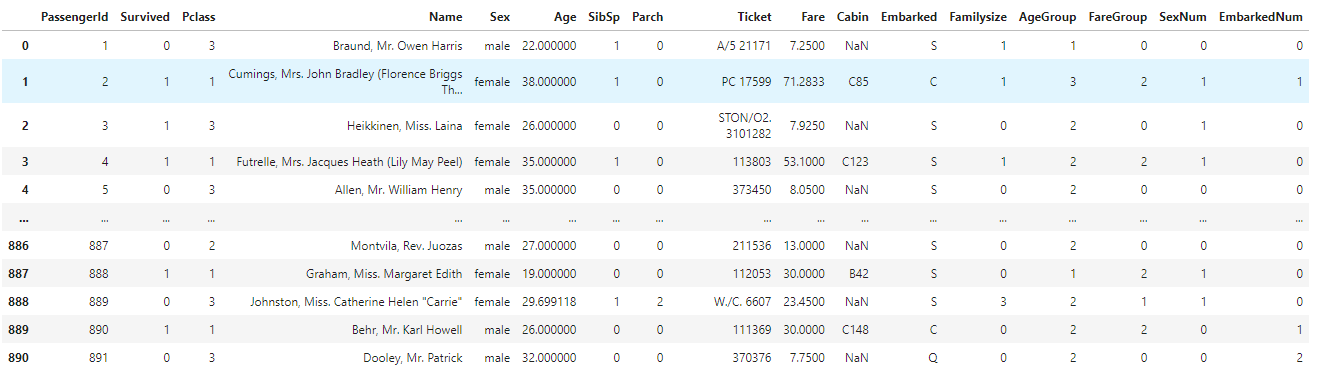
데이터 가공 후 다음과 같은 특성(Pclass,Familysize,AgeGroup,FareGroup,SexNum,EmbarkedNum)을 독립변수로 하여 Survived 를 예측하는 머신러닝 모델을 만들면 됩니다.
따라서 다음과 같이 data와 target 데이터를 생성 합니다.
target = train['Survived']
data = train[['Pclass','SexNum','AgeGroup','FareGroup','EmbarkedNum','Familysize']]
6. 모델 선택
위와 같이 데이터 생성 후 어떤 모델이 가장 적합한지 모델을 선택해 봅니다.
from sklearn.model_selection import train_test_split
#훈련세트와 테스트 세트 분리
train_input,test_input,train_target,test_target = train_test_split(data,target,test_size=0.2,random_state=42)
#어떤 알고리즘이 가장 성능이 좋은지 테스트 해 보자.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
#K_fold cross validation 준비, 10개 구역을 나눔.
k_fold = KFold(n_splits=10,shuffle=True,random_state=42)
#KNN
knn = KNeighborsClassifier(n_neighbors=5)
score_knn = cross_val_score(knn,train_input,train_target,cv=k_fold,n_jobs=1,scoring='accuracy')
#의사결정 트리
dt = DecisionTreeClassifier()
score_dt = cross_val_score(dt,train_input,train_target,cv=k_fold,n_jobs=1,scoring='accuracy')
#랜덤 포레스트
rf = RandomForestClassifier(n_estimators=10)
score_rf = cross_val_score(rf,train_input,train_target,cv=k_fold,n_jobs=1,scoring='accuracy')
#SVM
sv = svm.SVC(gamma='auto')
score_sv = cross_val_score(sv,train_input,train_target,cv=k_fold,n_jobs=1,scoring='accuracy')
#정확도 확인
print("KNN :",round(np.mean(score_knn)*100,2))
print("DecisionTree :",round(np.mean(score_dt)*100,2))
print("RandomForest :",round(np.mean(score_rf)*100,2))
print("SVM :",round(np.mean(score_sv)*100,2))
SVM 이 가장 높은 성능을 보이는 것을 확인 할 수 있습니다.
그러면 우리는 SVM 모델을 이용하여 모델을 구축하여 훈련을 해 보도록 하겠습니다.
7. 모델 훈련
#SVM으로 모델을 훈련하자
sv.fit(data,target)8. 테스트 데이터 예측
테스트 데이터도 같은 모양으로 만들어 줍니다.
#test 데이터도 train과 동일하게 데이터가공
test['Familysize']=test['SibSp'] + test['Parch']
#age 결측치 처리
#평균으로 결측치 채우기
test['Age'].fillna(test['Age'].mean(axis=0),inplace=True)
# age 구간화
# 청소년 : 0
# 청년 : 1
# 장년 : 2
# 중년 : 3
# 노년 : 4
ranges=[0,16,26,36,62,100]
labels=[0,1,2,3,4]
test["AgeGroup"]=pd.cut(test['Age'],ranges,right=False,labels=labels)
# fare 구간화
ranges=[0,17,30,100,1000]
labels=[0,1,2,3]
test["FareGroup"]=pd.cut(test['Fare'],ranges,right=False,labels=labels)
#성별을 숫자로 매핑
test['SexNum']=test['Sex'].apply(lambda x:1 if (x=='female') else 0)
#embarked을 숫자로 매핑
test['EmbarkedNum']=test['Embarked'].apply(lambda x:0 if (x=='S') else (1 if(x=='C') else 2))
test_data = test[['Pclass','SexNum','AgeGroup','FareGroup','EmbarkedNum','Familysize']]
print(test_data)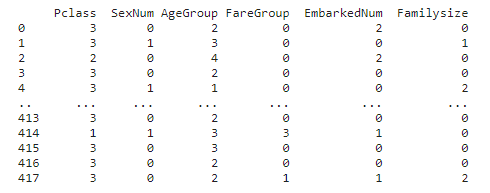
해당 모델로 예측을 해 봅니다.
pred = sv.predict(test_data)9. 훈련 결과 제출
submission = pd.DataFrame({
"PassengerId":test['PassengerId'],
"Survived": pred
})
submission.to_csv('submission.csv',index=False)output 폴더에 다음과 같이 submission.csv 파일이 생성 된 것을 확인 할 수 있습니다.
submission 파일이 잘 만들어 졌는지 확인해 봅니다.
submissionfile = pd.read_csv('/kaggle/working/submission.csv')
print(submissionfile.head())
제출하기 전 커밋(commit)을 합니다.
- 오른 쪽 상단의 Save Version 버튼 클릭

- 커밋 창이 뜨면 Version Name을 쓴 뒤(생략 가능) Save 버튼을 눌러서 저장
- 왼쪽 하단에 다음과 같이 커밋을 진행 한다.
- 제출 및 점수 확인
커밋을 했으니 이제 제출해 보자
- Save Version 옆에 숫자가 0 에서 1로 변경 되어 있다.
- 1로 표시된 영역을 클릭 후 Go to Viewer 를 클릭 하면 지금까지 작성한 코드를 확인 할 수 있다.
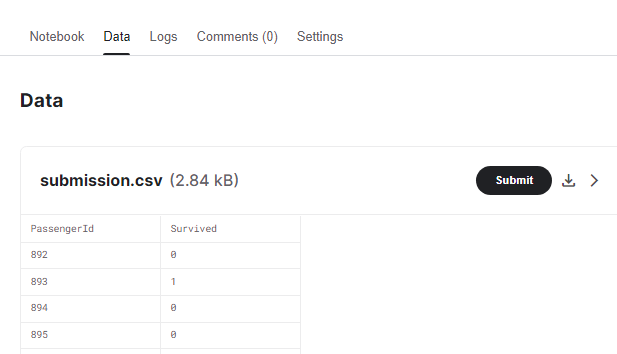
- Data를 클릭하면 업로드 된 submission.csv 파일을 확인 할 수 있고 여기서 Submit 버튼을 클릭해서 제출한다.
- 제출 완료 후 View My Submissions를 클릭해서 확인 가능하다.
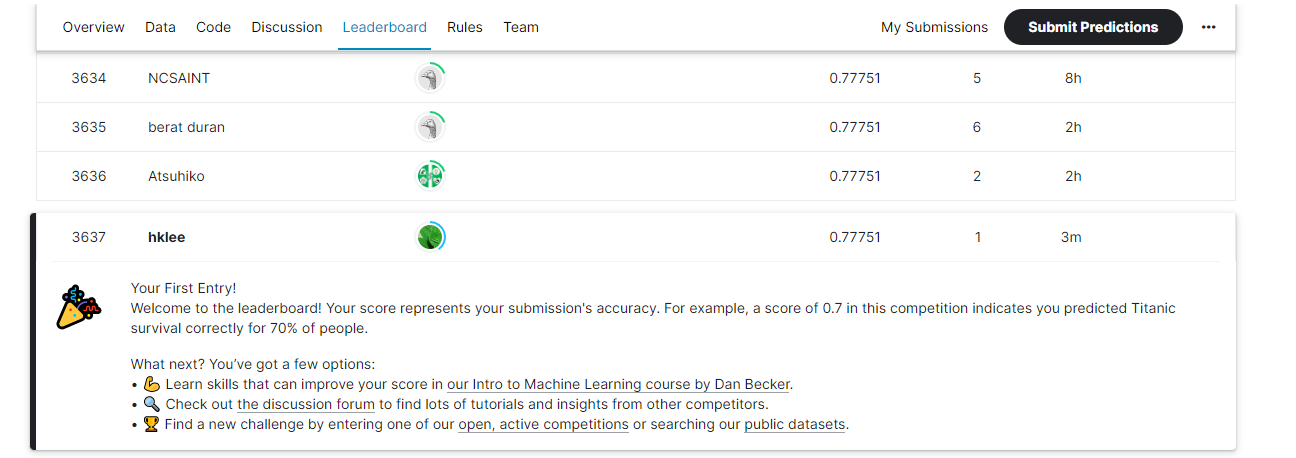
- 점수를 확인해 보면 0.77751 를 확인 할 수 있다.

이 점수는 0 부터 1 사이의 점수이므로 77프로 확률로 맞췄다는 의미이다.
10. 등수 확인
Leaderboard 탭에서 자신의 등수를 확인 할 수 있다
캐글의 첫번째 도전 과제 타이타닉을 훌륭히 해 내셨습니다.^^
수고하셨습니다.^^
'강의자료 > 머신러닝' 카테고리의 다른 글
| 머신러닝 목차 (0) | 2024.02.29 |
|---|---|
| 머신러닝] 교차검증으로 평가하기 (18) | 2023.12.13 |
| [머신러닝 따라하기] 01.데이터 준비 (0) | 2022.09.30 |
| 9.1 타이타닉 경진대회 참여하기 (9) | 2022.09.30 |
| 9.1 캐글이란 (6) | 2022.09.23 |